The representational power of synthetic images in Text-to-image models — computationally aggregated approximations of real sites—offers unprecedented opportunities for collective imagination. However, the dramatic proliferation of AI-generated imagery raises critical concerns about the authenticity and fidelity of computationally-led representations of place.
If an estimated
90%
of images online
may be AI-generated
by 20261
How do current GenAI models perpetuate biased representations of place?
Currently: 34 million AI images2 are created daily
While extensive research on AI bias has focused on human representation—how systems depict different ethnicities, genders, and cultures—there has been little attention paid to how text-to-image models represent place & locality: the built environments and landscapes that shape our understanding of different cultures and communities.

Of concern are the implications for regions underrepresented in the underlying datasets fueling these AI systems—particularly in the "global south". The images of localities conjured by the mere usage of "global south" implies a texture of neglect and equality in carrying a seat within the global conversations within today's datasets.
Our work examines how synthetic place generation affects our understanding and representation of global localities. This shift from studying bias against people to focusing on the compression of place offers complementary insights into how AI models construct and represent our physical world. Here, we compare the treatment of two mechanically-captured images (photographs) index the personal vision of Judd's Mother in her home country of Guyana and abroad on a visit in France.

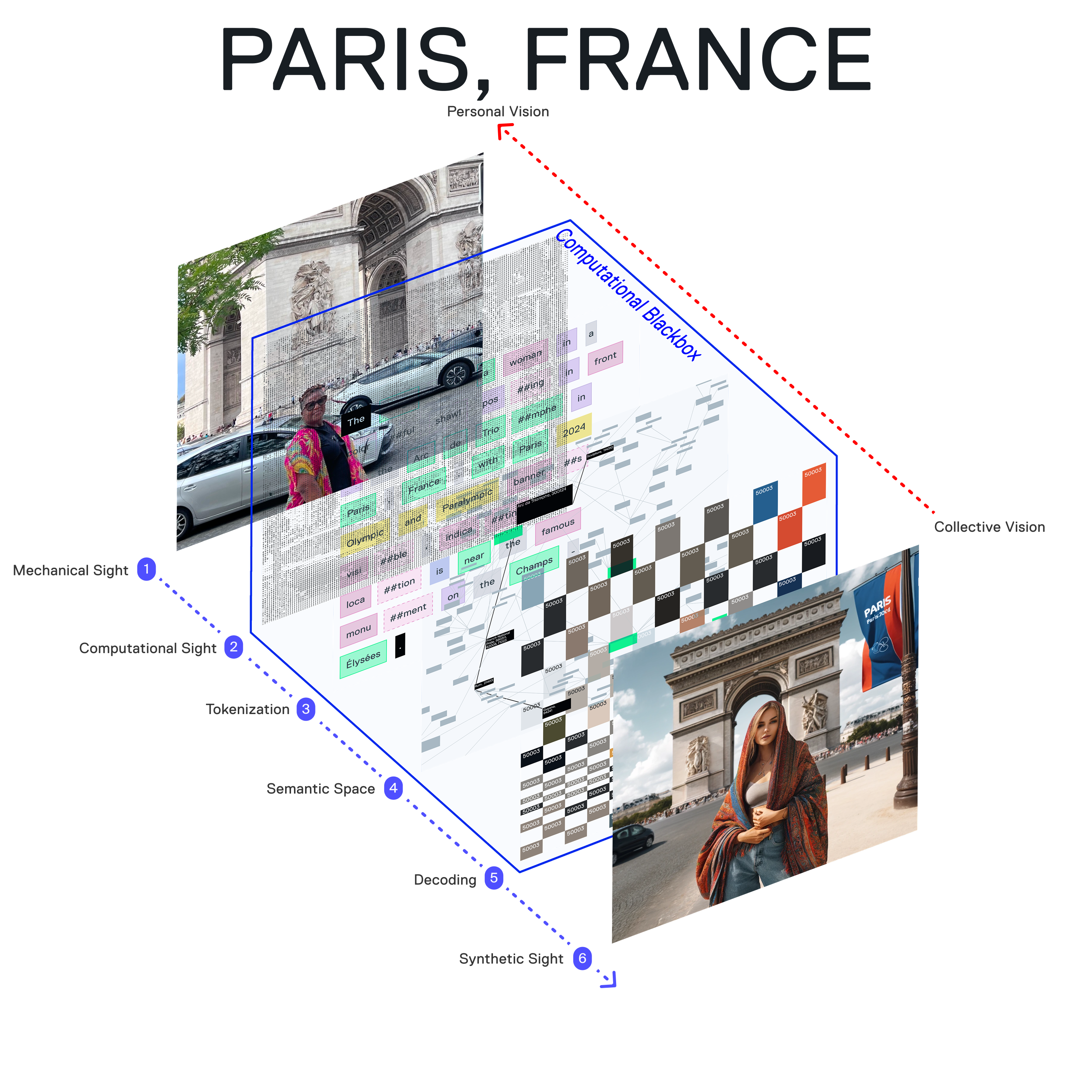
Using a multimodal model, computer vision devoid of personal and cultural context only sees "a woman in a colorful shawl" by the "Arc de Triomphe" or "two women… at what appears to be Stabroek Market in Georgetown, Guyana." Tokenization fragments the semiotic connections into unbound radicals that are easily reassembled into distant interpretations. The model's latent semantic space draws its own cartography of meaning to map tokens into a semantic space where synthetic grafting begins—it is here that Georgetown, Guyana suddenly relates to Georgetown University and the Potomac River in Washington DC. Because instances of Paris' associative meaning are over-indexed, its semantic space is restricted within France. Decoding then faithfully reproduces these instances and in the process splices and appends well-indexed representations to their under-represented counterparts — the "colorful shawl" becomes the "exotic fabric" worn by a travel influencer. The final output we collectively see erases the personal vision, leaving us only with the synthetic simulacra of cultural relevance of place.
In the age of AI, we must stem misrepresentation in synthetic imagery, and provoke ethical tools that protect and celebrate the nuanced poetics of locality.
Venice, Italy & Ganvie, Benin


Methodology
48 global destinations
24 Global North / 24 Global South
StabilityAI_Stable_Diffusion_3.5_Large
Wikimedia Commons as ground truth
- First systematic study of place-based bias in AI
- Global North/South comparative analysis
- Novel methodology combining GIS + AI
- Focus on built environment & cultural spaces
Special thanks to Johan MichaloveSemioscape.org for providing the "concept cartographer" tool used in our semantic network research and visualization development.